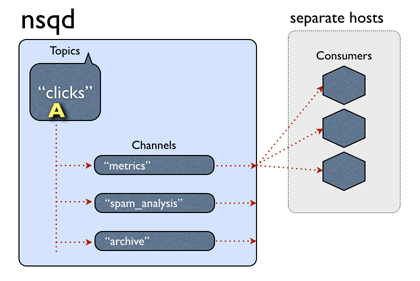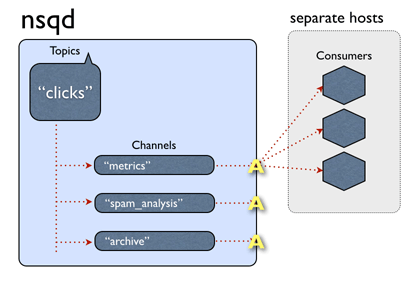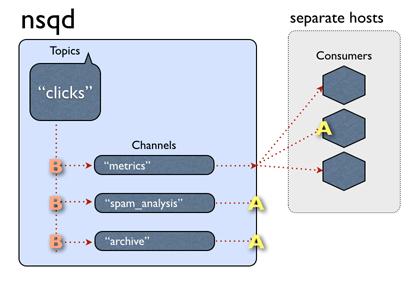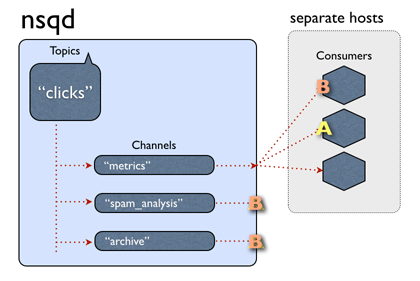
sudo mount -t vfat -o uid=pi,gid=pi /dev/sda1 ./src_boot # Mount boot partition sudo mount -t ext4 /dev/sda2 ./src_boot # Mount root partition
Then use sudo df -h to check it.
pi.img: Create empty file
Use df -h to checkout size of /dev/sda1 and /dev/sda2, caculate FILESIZE=/dev/sda1.Size+/dev/sda2.Used. It’s a good idea to add more size to FILESIZE, e.g. 1G.
Then create an empty file(example with FILESIZE=5G):
cd dst_root/ sudo dump -0auf - ../src_root/ | sudo restore -rf - # Dump filesystem from `src_root/`, and restore to `dst_root/`
On success DUMP IS DONE will be printed out. If there is Broken pipe error, use df -h to check if Avail of /dev/mapper/loo0p2 greater than Used of /dev/sda2.
Modify boot/fstab
Use sudo blkid to check PARTUUID of boot partition and root partition, print info as below:
运行期的多态,是很多高级语言的很重要的特性。我们可以在运行期根据实际创建的对象,决定实际所要运行的函数。 C++可以通过virtual member function实现运行期的多态,同样,在Go我们可以通过interface实现类似的机制。虽然C++的virtual和Go的interface本质上还是有很多区别,但是不妨碍我们深入探讨一下关于如何实现运行期多态。
## Go interface Go的interface是Go语言一个很重要的设计,借鉴了Java和C++的部分语言特性,最大的改变是去掉了C++和Java里面的显示继承。interface只是单纯的定义分行为(方法),如果我们要定义一种类型属于该interface,并不需要显示的继承该interface,只需要对该类型实现所有interface所声明的方法,那么这个类型就是属于该interface。
这里涉及的设计哲学是`What I do makes who I am`,不同于C++/Java的`I declare who I am`。这是一种充分`解耦`的设计哲学,打破 了类型之间的强耦合。其实跟现实世界很像,你是什么样的人,不取决于你自己怎么说或者你身上的既定的标签,而取决于你自己的行为。例如,你成天跟大家说你是君子不代表你就是一个君子,你的君子行径才能决定。嗯,有点跑题了,我们还是回到正轨。
注意:我们需要区分一下Node和Peer的概念,以下是DHT的papper的描述 A “peer” is a client/server listening on a TCP port that implements the BitTorrent protocol. A “node” is a client/server listening on a UDP port implementing the distributed hash table protocol.
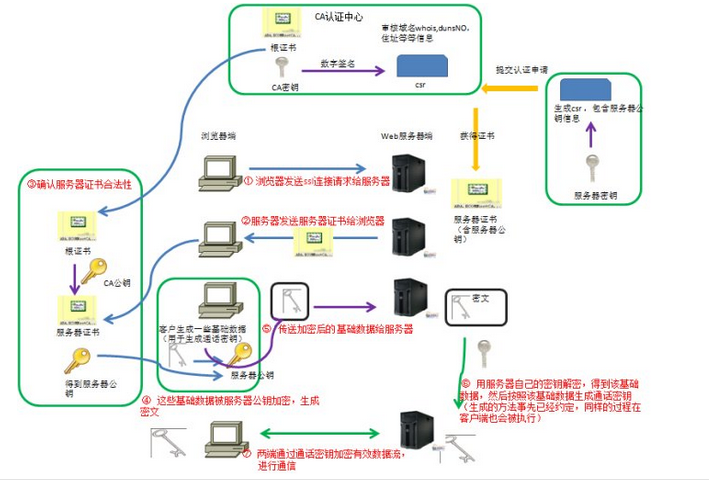
openssl req -new -key server_key.pem -out server_csr.pem ... Country Name (2 letter code) [AU]:CN State or Province Name (full name) [Some-State]:GD Locality Name (eg, city) []:SZ Organization Name (eg, company) [Internet Widgits Pty Ltd]:COMPANY Organizational Unit Name (eg, section) []:IT_SECTION Common Name (e.g. server FQDN or YOUR name) []:your.domain.com Email Address []:
Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []: ...
这是Stack Overflow上面的一句话 The maximum safe UDP payload is 508 bytes. This is a packet size of 576, minus the maximum 60-byte IP header and the 8-byte UDP header. Any UDP payload this size or smaller is guaranteed to be deliverable over IP (though not guaranteed to be delivered). Anything larger is allowed to be outright dropped by any router for any reason. 按照字面理解的意思是,大于576的udp包在路由链路保证不了一定传输,难道是路由器的实现潜规则?
更新At 2016-11-14
RFC的IPV4标准里面有定义。
RFC 791 excerpt: … All hosts must be prepared to accept datagrams of up to 576 octets ( whether they arrive whole or in fragments ). It is recommended that hosts only send datagrams larger than 576 octets if they have assurance that the destination is prepared to accept the larger datagrams. The number 576 is selected to allow a reasonable sized data block to be transmitted in addition to the required header information. For example, this size allows a data block of 512 octets plus 64 header octets to fit in a datagram. The maximal internet header is 60 octets, and a typical internet header is 20 octets, allowing a margin for headers of higher level protocols. …