1. 背景
BT作为历史上最成功的P2P文件系统,已经在全球实现了彻底的去中心化。BT的P2P网络,不依赖任何机构或者中心依然能够很好的运行。
这里面,最关键的设计是引入了DHT。这里我们主要介绍一下为什么要引入DHT,以及DHT的基本原理。
BT作为一种P2P系统,面临资源索引问题,简单来说资源索引维护资源(resource)当前有哪些节点(peer)也在同时下载的关系。
1 | res0 -> peerA,peerB,... |
2. 中心化
BT的数据传输本身是去中心化的,每一个peer会同时从网络上搜索到的其它peer进行数据传输。
但是资源索引一开始还是中心化的解决方案,就是Tracker。虽然网络上有很多提供Tracker的服务,每一个客户端也可以设置若干个Tracker,但是Tracker依然是一个中心化的服务。
Tracker原理很简单,提供了上报和查询服务。如下图:正在下载某一个资源(res)的BT客户端peer2把资源上报给Tracker。下载资源的BT客户端(peer1)可以到Tracker查询时下载这个资源的peer2。
1 |
|
Tracker提供了一种简单高效的方案,解决了资源索引的问题。缺点是一旦Tracker不可用,BT的P2P网络也就随之瘫痪(可以参考海盗湾事件)。这是所有中心化服务必将面临的问题,为了让整个P2P网络更加健壮,需要探索一个去中心化的实现。
3. 去中心化
考虑没有中心化的Tracker,我们需要一个去中心化的方式,把资源的索引存储(sharding)到全网的节点,并且能高效的查询。
3.1 全量
最简单的办法,就是让每一个Node(节点)都维护一个全量的索引,相当于每个Node都是一个Tracker节点。
注意:我们需要区分一下Node和Peer的概念,以下是DHT的papper的描述
A “peer” is a client/server listening on a TCP port that implements the BitTorrent protocol. A “node” is a client/server listening on a UDP port implementing the distributed hash table protocol.
1 | -------------- ----------------------------------- |
这种方案有几个明显的问题
- 每个索引的变更需要扩散到全网,效率太差
- 海量的索引,每个单点都需要全量存储,代价太大
3.2 Sharding
基本的思路是,我们需要把索引数据按照一定规则分布(sharding)到全网的节点。
1 | ----------- ----------- ----------- ----------- |
一致性Hash是一种常用的办法,首先把Node散列(hash
同样,我们可以把资源也计算一个整数的hash。
例如,NodeA负责范围[i, j)的范围,那么如果索引按照分布规则在范围内,那么该索引就由NodeA负责存储。
1 | // NodeA covers [i, j). |
这里盗用一个网上的一致性Hash图片,具体的算法这里就不重复介绍了。
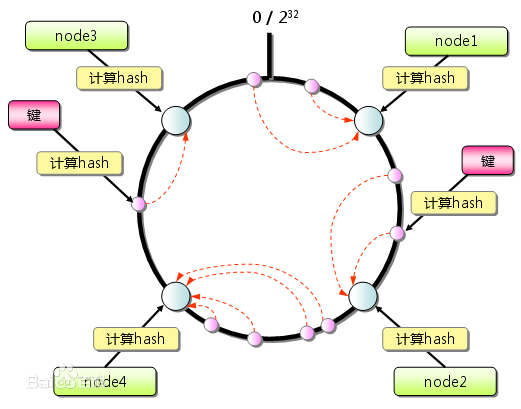
一致性Hash解决了sharding的问题,但是一致性Hash引入了Hash环状态。在系统中如何维护Hash状态数据,跟如何维护资源索引面临一样的问题。
我们需要彻底解决状态数据的问题,才能真正实现去中心化。
4. DHT
DHT(Distributed Hash Table),就是分布式Hash table。实际上也是Sharding的一种实现方法,DHT可以看作是一致性Hash的基础上的改进。一致性Hash算法的问题是Hash环的状态数据,只要我们能设计出一种关于索引分布规则的去中心化的共识机制,我们并不需要去维护一个Hash环。关于DHT的比较完整的介绍,可以参考DHT Protocol。
DHT设计了这样一种去中心化的共识机制:索引信息应该存储到到距离目标更近的节点。
4.1 Hash
DHT网络中每个节点的NodeID就是一个hash值,每个资源也有一个hash。
4.2 距离
用来计算2个hash的距离,Node和Node之间可以有距离,Node和资源之间也可以有距离。要注意的是,这个距离并不是实际意义上的距离,只是一个算法上的需要。
4.3 Routing table
DHT网络中每个Node都维护一个Routing table(路由表),这是DHT的核心部分,它保存本节点和网络中一小部分节点信息。每一个节点,都能够提供查询接口,并且能够返回距离目标hash更近的节点。这样通过网络中递归查询Routihng table,可以不断的趋向更近。IPFS把这个过程总结为Peer Routing的过程。我们可以用Peer routing解决DHT的共识机制。
1 | --------------------------------------------- |
我们以查询资源为例,一个典型的Query Resource过程:
1 | 1 ) client需要查找目标资源hash,先到Node0进行查询。 |
5. Kademlia
DHT有很多不同的实现,这里主要介绍Kademlia,一般我们叫KAD。现在大部分的DHT都是基于KAD实现,或者KAD的一些改进。
KAD使用k-bucket(k桶)实现Routing table,能实现log2(N)的查找效率。假设1000000节点的规模的网络,可以最多20次查询能够完成全网节点的查询。
关于KAD的实现有很多细节,我们这里着重介绍为什么k-bucket能实现log2(N)的查找效率。
5.1 距离
KAD使用XOR(按位异或)对两个hash进行距离计算,为什么要使用异或?我们后面结合k桶可以看到,这是经过精心设计的算法。
1 | distance(A, B) = A xor B |
5.2 Routing table
KAD使用K桶(K-bucket)实现Routing table,K桶实际上是一个hash table。Hash table的大小取决于我们使用hash的位数,因为KAD使用sha1做hash算法,sha1的hash结果为160位,所以KAD的K桶大小为160。
那么K是什么意思呢,KAD限制了每个桶最多能存储K个节点信息,所以叫K桶。默认的KAD实现K一般为8。
实际的实现是K桶大小初始化为1,随着每个桶的节点数量超过K,K桶会进行对半分裂。由于不是关键点,我们这里就不详细介绍。
1 | ----------------------------------------------------------------------- |
5.3 K桶算法
那么,一个NodeInfo应该放到哪个桶呢。KAD的算法是,越小(具体实现也可能是越大,算法本质都一样)的桶存储的NodeInfo距离本节点的ID越远,并且每递增一个桶,距离折半。可以用按bit前缀匹配来实现,简单来说,第N个桶存储的节点NodeID与当前节点的NodeID前N-1位相同,第N位不同。
上面的描述还是有点晦涩,大家可以简单推算一下(XOR计算距离),第0个桶上面的NodeInfo的ID所有的bit跟本节点ID都不一样(距离2^N,最远),最后一个桶的NodeInfo的ID只有最后一个bit跟本节点ID不一样(距离2^0=1)。
按照这个算法,有几个比较明显的结论是:
- 越大的桶存储的是离本节点越近的节点信息(XOR计算距离)
- 第N+1个桶存储的节点,比第N个桶存储的节点,距离本节点近了一半。也就是每递增一个桶,节点数量折半。
- 桶内所有的节点之间的距离,都一定比桶内节点跟本节点的距离,至少更近一半。(桶内节点跟本节点第N位不同,那么这些节点之间的第N位一定相同,也就是这些节点之间的前N位都相同)
我门用一个K桶大小为4的例子说明:
1 | // 假如节点0000保存了全部节点信息,实际上网络很大的时候一个节点的K桶只会保存一部分节点信息 |
可以看到:
- 第1个桶节点和本节点距离,比第0个桶节点和本节点的距离,更近。(例如 (0100 xor 0000 = 0100) < (1000 xor 0000 = 1000) )
- 第1个桶的节点数量,是第0个桶节点数量的一半。也就是越大的桶,节点数量是折半。
- 第0个桶,内部的节点距离,会比本节点距离至少更近一半。(例如 1000 xor 1001 = 0001, 1000 xor 0000 = 1000)
5.4 折半效率
所以,为什么KAD能够实现log2(N)的折半查找效率呢。
假如我们要查找/存储的目标为资源target,第一轮查询我们到节点Node0进行查询,Node0进行的操作为:
- 如果Node0拥有target资源,则返回
- 否则,计算target和Node0的距离所对应的K桶,例如为N
- 返回第N个桶的K个新节点信息
考虑第3)步,返回给客户端的这K个新节点,我们很容易得出一个结论:target和新节点的距离,至少比和Node0的距离近一半。
由于target和Node0计算距离定位到第N个桶,也就是target和Node0也是前缀关系,前N-1位相同,第N位不同。
再由于,”桶内所有的节点之间的距离,都一定比桶内节点跟本节点的距离,至少更近一半“。
客户端拿到离目标更近一半的新节点,继续进行下一轮查询,每递归一轮查找都能折半趋近。
6 结论
虽然我们这里忽略了很多DHT和KAD的实现细节,但是可以看到KAD通过K桶的Peer routing,能够实现折半效率的Peer routing。从而,我们可以通过Peer routing查找/存储到距离目标最近的节点,实现一个共识机制。
DHT作为去中心化的实现,相对中心化的Tracker,牺牲的是效率(慢扩散查找)和一致性(最终一致),换来的是网络的健壮性。